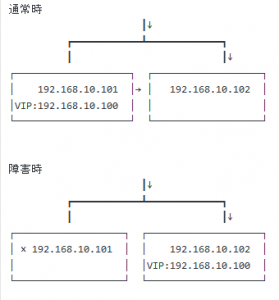
JIS(≒ISO-2022-JP)で定義されていない文字コードは、UTF8から変換しても、もちろん正常に表示されません。
しかし日本語のUTF8には、実は、濁点と半濁点をふくむ文字に2パターンの表示方法があります。
たとえば「が」というひらがなですが、普通は、
xE3x81x8C
となります。
しかし、UTF8の決まりでは、
xE3x81x8B + xE3x82x99 (「か」+「 ○゛」)
でもOKなのです。
うちでは日本語文字コードの変換にUnicode::Japaneseを使ってます。非常に多くの変換パターンが実現できるので便利なのですが、上記の後者の場合(「か」+「 ○゛」の場合)に、UTF8→JISなどの変換に失敗します。
失敗というか、厳密にはxE3x82x99( ○゛)とxE3x82x9A( ○゜)が未定義状態のようで、「が」は「が」のように変換されてしまいます。
エンコーダを変えればいいのかもしれませんが、やはりバグが怖いので、下記のようにJISへの変換前にコードを統一することで対応してます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
$str = "がぎぐげござじずぜぞだぢづでど・・・"; # Hiragana $str =~ s/\xE3\x81\x8B\xE3\x82\x99/\xE3\x81\x8C/g; # か+○゛=> が $str =~ s/\xE3\x81\x8D\xE3\x82\x99/\xE3\x81\x8E/g; # き+○゛=> ぎ $str =~ s/\xE3\x81\x8F\xE3\x82\x99/\xE3\x81\x90/g; # く+○゛=> ぐ $str =~ s/\xE3\x81\x91\xE3\x82\x99/\xE3\x81\x92/g; # け+○゛=> げ $str =~ s/\xE3\x81\x93\xE3\x82\x99/\xE3\x81\x94/g; # こ+○゛=> ご $str =~ s/\xE3\x81\x95\xE3\x82\x99/\xE3\x81\x96/g; # さ+○゛=> ざ $str =~ s/\xE3\x81\x97\xE3\x82\x99/\xE3\x81\x98/g; # し+○゛=> じ $str =~ s/\xE3\x81\x99\xE3\x82\x99/\xE3\x81\x9A/g; # す+○゛=> ず $str =~ s/\xE3\x81\x9B\xE3\x82\x99/\xE3\x81\x9C/g; # せ+○゛=> ぜ $str =~ s/\xE3\x81\x9D\xE3\x82\x99/\xE3\x81\x9E/g; # そ+○゛=> ぞ $str =~ s/\xE3\x81\x9F\xE3\x82\x99/\xE3\x81\xA0/g; # た+○゛=> だ $str =~ s/\xE3\x81\xA1\xE3\x82\x99/\xE3\x81\xA2/g; # ち+○゛=> ぢ $str =~ s/\xE3\x81\xA4\xE3\x82\x99/\xE3\x81\xA5/g; # つ+○゛=> づ $str =~ s/\xE3\x81\xA6\xE3\x82\x99/\xE3\x81\xA7/g; # て+○゛=> で $str =~ s/\xE3\x81\xA8\xE3\x82\x99/\xE3\x81\xA9/g; # と+○゛=> ど $str =~ s/\xE3\x81\xAF\xE3\x82\x99/\xE3\x81\xB0/g; # は+○゛=> ば $str =~ s/\xE3\x81\xAF\xE3\x82\x9A/\xE3\x81\xB1/g; # は+○゜=> ぱ $str =~ s/\xE3\x81\xB2\xE3\x82\x99/\xE3\x81\xB3/g; # ひ+○゛=> び $str =~ s/\xE3\x81\xB2\xE3\x82\x9A/\xE3\x81\xB4/g; # ひ+○゜=> ぴ $str =~ s/\xE3\x81\xB5\xE3\x82\x99/\xE3\x81\xB6/g; # ふ+○゛=> ぶ $str =~ s/\xE3\x81\xB5\xE3\x82\x9A/\xE3\x81\xB7/g; # ふ+○゜=> ぷ $str =~ s/\xE3\x81\xB8\xE3\x82\x99/\xE3\x81\xB9/g; # へ+○゛=> べ $str =~ s/\xE3\x81\xB8\xE3\x82\x9A/\xE3\x81\xBA/g; # へ+○゜=> ぺ $str =~ s/\xE3\x81\xBB\xE3\x82\x99/\xE3\x81\xBC/g; # ほ+○゛=> ぼ $str =~ s/\xE3\x81\xBB\xE3\x82\x9A/\xE3\x81\xBD/g; # ほ+○゜=> ぽ # Katakana $str =~ s/\xE3\x82\xAB\xE3\x82\x99/\xE3\x82\xAC/g; # カ+○゛=> ガ $str =~ s/\xE3\x82\xAD\xE3\x82\x99/\xE3\x82\xAE/g; # キ+○゛=> ギ $str =~ s/\xE3\x82\xAF\xE3\x82\x99/\xE3\x82\xB0/g; # ク+○゛=> グ $str =~ s/\xE3\x82\xB1\xE3\x82\x99/\xE3\x82\xB2/g; # ケ+○゛=> ゲ $str =~ s/\xE3\x82\xB3\xE3\x82\x99/\xE3\x82\xB4/g; # コ+○゛=> ゴ $str =~ s/\xE3\x82\xB5\xE3\x82\x99/\xE3\x82\xB6/g; # サ+○゛=> ザ $str =~ s/\xE3\x82\xB7\xE3\x82\x99/\xE3\x82\xB8/g; # シ+○゛=> ジ $str =~ s/\xE3\x82\xB9\xE3\x82\x99/\xE3\x82\xBA/g; # ス+○゛=> ズ $str =~ s/\xE3\x82\xBB\xE3\x82\x99/\xE3\x82\xBC/g; # セ+○゛=> ゼ $str =~ s/\xE3\x82\xBD\xE3\x82\x99/\xE3\x82\xBE/g; # ソ+○゛=> ゾ $str =~ s/\xE3\x82\xBF\xE3\x82\x99/\xE3\x83\x80/g; # タ+○゛=> ダ $str =~ s/\xE3\x83\x81\xE3\x82\x99/\xE3\x83\x82/g; # チ+○゛=> ヂ $str =~ s/\xE3\x83\x84\xE3\x82\x99/\xE3\x83\x85/g; # ツ+○゛=> ヅ $str =~ s/\xE3\x83\x86\xE3\x82\x99/\xE3\x83\x87/g; # テ+○゛=> デ $str =~ s/\xE3\x83\x88\xE3\x82\x99/\xE3\x83\x89/g; # ト+○゛=> ド $str =~ s/\xE3\x83\x8F\xE3\x82\x99/\xE3\x83\x90/g; # ハ+○゛=> バ $str =~ s/\xE3\x83\x8F\xE3\x82\x9A/\xE3\x83\x91/g; # ハ+○゜=> パ $str =~ s/\xE3\x83\x92\xE3\x82\x99/\xE3\x83\x93/g; # ヒ+○゛=> ビ $str =~ s/\xE3\x83\x92\xE3\x82\x9A/\xE3\x83\x94/g; # ヒ+○゜=> ピ $str =~ s/\xE3\x83\x95\xE3\x82\x99/\xE3\x83\x96/g; # フ+○゛=> ブ $str =~ s/\xE3\x83\x95\xE3\x82\x9A/\xE3\x83\x97/g; # フ+○゜=> プ $str =~ s/\xE3\x83\x98\xE3\x82\x99/\xE3\x83\x99/g; # ヘ+○゛=> ベ $str =~ s/\xE3\x83\x98\xE3\x82\x9A/\xE3\x83\x9A/g; # ヘ+○゜=> ペ $str =~ s/\xE3\x83\x9B\xE3\x82\x99/\xE3\x83\x9C/g; # ホ+○゛=> ボ $str =~ s/\xE3\x83\x9B\xE3\x82\x9A/\xE3\x83\x9D/g; # ホ+○゜=> ポ |
ご自由にコピペどうぞ。
参考サイト)
http://d.hatena.ne.jp/kamosawa/20151015
http://www.seiai.ed.jp/sys/text/java/utf8table.html
http://webmastertool.jp/other/utf.html
http://www.asahi-net.or.jp/~ax2s-kmtn/ref/unicode/u3040.html