プライマリとスレーブのDB(MySQL)サーバを準備し、マスターがLVS(バランシング)も兼ねる。
通常はマスターに来たパケットを半分スレーブに流す。
またお互いに監視しあって、マスターがダウンした場合にスレーブがマスターに昇格するフェイルオーバ機能を作る。
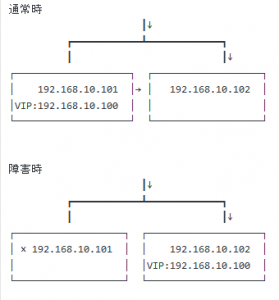
※なおクラウドの場合、VIPが設定できなかったり、バケット転送ができないようになっている場合があるので、注意が必要。
以下、マスターのみの設定。
まずバランサのためipvsadm のインストール
いろいろ事前にインストールが必要らしい
# yum install -y kernel-devel
カーネルのIP_VSのバージョンを確認
# grep IP_VS_VERSION_CODE /usr/src/kernels/2.6.18-194.32.1.el5-i686/include/net/ip_vs.h
(32bitの場合は「2.6.18-194.32.1.el5-i686」を「2.6.18-194.32.1.el5-i386」に読み替える)
——————–
-> 0x010201
——————–
これはどうやらバージョン 1.2.1。
IP_VS_VERSION_CODE 1.2.1 に該当する ipvsadm は 1.24 である為、これをソースコードからインストール。
# cd /usr/local/src
# wget http://www.linux-vs.org/software/kernel-2.6/ipvsadm-1.24.tar.gz
# tar zxvf ipvsadm-1.24.tar.gz
# cd ipvsadm-1.24
# mkdir -p /usr/src/linux
# ln -s /usr/src/kernels/2.6.18-194.32.1.el5-i686/include /usr/src/linux/include# make
# make -e BUILD_ROOT=/usr/local install
パスを通す
# cd ~/
# vi .bash_profile
以下を追記
——————–
PATH=${PATH}:/usr/local/sbin
export PATH
——————–
# source ~/.bash_profile
バージョン確認
# ipvsadm -v
——————–
-> ipvsadm v1.24 2005/12/10 (compiled with popt and IPVS v1.2.1)
——————–
v1.2.1なので、OK。
バランシング設定
192.168.10.100のVIPに来たDBアクセスをラウンドロビンさせる場合
# ipvsadm -A -t 192.168.10.100:3306 -s rr
追加された事を確認する。
# ipvsadm -Ln
—————————–
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.10.100:3306 rr
—————————–
VIP(192.168.10.100)で接続されたものを、次のサーバーへ転送する設定
192.168.10.100からリアルサーバのIPアドレスの192.168.10.101を追加。
# ipvsadm -a -t 192.168.10.100:3306 -r 192.168.10.101 -g
192.168.10.100からリアルサーバのIPアドレスの192.168.10.102を追加。
# ipvsadm -a -t 192.168.10.100:3306 -r 192.168.10.132 -g
確認
# ipvsadm -Ln
—————————–
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.10.100:3306 rr
-> 192.168.10.101:3306 Route 1 0 0
-> 192.168.10.102:3306 Route 1 0 0
—————————–
OSが再起動されたときに消えないように保存。
# ipvsadm -S
IPフォワード(パケット転送)の設定とARP設定
# vi /etc/sysctl.conf
————–
:
# Controls IP packet forwarding
#net.ipv4.ip_forward = 0
net.ipv4.ip_forward = 1
:
————–
設定内容反映
# sysctl -p
# cat /proc/sys/net/ipv4/ip_forward
————–
->1
————–
1と表示されればOK
以下、マスターとスレーブ共通
ifcfg-eth0:0など、VIP用の設定ファイルを削除またはリネーム。当然ネットワークはrestart。
# cd /etc/sysconfig/network-scripts
# mv ifcfg-eth0:0 ifcfg-eth0:0.bak
:
# /etc/init.d/network restart
ローカルループバックアドレスにVIPアドレスを設定する。
#vi /etc/sysconfig/network-scripts/ifcfg-lo:0
—————————–
DEVICE=lo:0
IPADDR=192.168.10.100
NETMASK=255.255.255.255
ONBOOT=yes
—————————–
ネットワーク再起動
# /etc/init.d/network restart
keepalivedインストール
残念ながらyumにkeepalivedは無い。
まず依存関係インストール
# yum -y install make kernel kernel-devel rpm-build openssl-devel
keepalivedソースコード取得
# cd /usr/local/src
# wget http://www.keepalived.org/software/keepalived-1.1.20.tar.gz
# tar zxvf keepalived-1.1.20.tar.gz
# cd ./keepalived-1.1.20
# chown -R root:root /root/keepalived-1.1.20
# ./configure
RPMからインストール
# cp /usr/local/src/keepalived-1.1.20.tar.gz /usr/src/redhat/SOURCES/
# rpmbuild -ba ./keepalived.spec
# cd /usr/src/redhat/RPMS/x86_64(32bitの場合はi386)
# rpm -ivh ./keepalived-1.1.20-5.x86_64.rpm(32bitの場合はkeepalived-1.1.20-5.i386.rpm)
# チェック
keepalived -version
keepalived.confの「notify_master」と「notify_backup」を使い下記を現在のLVS STATEにより切り替える
LVSとリアルサーバが同一筐体の場合、
・master機の時は、VIPに対するarp応答をする
・slave機の時は、VIPに対するarp応答をしない
このためのShellを作る。
MASTER時用
# touch /etc/keepalived/lvs_master.sh
————————————-
#!/bin/sh
#lvs master起動時にARP応答する
/bin/sed -i -e ‘s/net.ipv4.conf.all.arp_ignore = 1//g;s/net.ipv4.conf.all.arp_announce = 2//g’ /etc/sysctl.conf
/sbin/sysctl -p
————————————-
スレーブ時用
# touch /etc/keepalived/lvs_backup.sh
————————————-
#!/bin/sh
#lvs backup起動時にARP応答を無効化する
/bin/echo ‘net.ipv4.conf.all.arp_ignore = 1’|/usr/bin/tee -a /etc/sysctl.conf
/bin/echo ‘net.ipv4.conf.all.arp_announce = 2’|/usr/bin/tee -a /etc/sysctl.conf
/sbin/sysctl -p
————————————-
※net.ipv4.conf.all.arp_ignore = 1 および net.ipv4.conf.all.arp_announce = 2
は、MACアドレスを覚えさせないようにする為、arpに応答させないための設定。
arpに返答してしまうと、MACアドレスを覚えてしまい、ipとmacアドレスが関係付けられてしまい送りたい機器へ通信がいかなくなるため。
設定ファイル編集
# vi /etc/keepalived/keepalived.conf
マスター側
————————————-
global_defs {
notification_email {
# 通知を受けるメールアドレス
down_notice@fuga.com
}
notification_email_from mysql1@hoge.com
smtp_server localhost
smtp_connect_timeout 30
}
vrrp_instance VI_1 {
state MASTER
# バーチャルIPのインターフェイス
interface eth1
# VRRPのID(共通)
virtual_router_id 105
# 優先度。スレーブより高くしておく
priority 51
# Master から送信する死活情報の秒指定
advert_int 1
# Master が落ちて Slave に系切り替えし、再度 Master が起動した
# 場合に Slave -> Master へ系切り替えをしないようにしたい場合は
# この nopreempt(Option 不要) を有効にする
#nopreempt
authentication {
auth_type PASS
auth_pass secret
}
virtual_ipaddress {
# バーチャルIP(keepalived が起動時に有効化するIP)を指定。
# 必ずバーチャルで付与したIP(例えば ip addr show したとき、
#「eth1」ではなく「eth1:1」となっている方のIP)を指定。
192.168.10.100 dev eth1
}
notify_master “/bin/sh /etc/keepalived/lvs_master.sh”
notify_backup “/bin/sh /etc/keepalived/lvs_backup.sh”
}
virtual_server 192.168.10.100 3306 {
# ヘルスチェックの間隔(秒)
delay_loop 120
lvs_method DR
protocol TCP
real_server 172.16.10.101 3306 {
TCP_CHECK {
connect_port 3306
connect_timeout 30
}
}
real_server 172.16.10.102 3306 {
TCP_CHECK {
connect_port 3306
connect_timeout 30
}
}
}
————————————-
スレーブ側
————————————-
global_defs {
notification_email {
down_notice@fuga.com
}
notification_email_from mysql2@hoge.com
smtp_server localhost
smtp_connect_timeout 30
}
vrrp_instance VI_2 {
state BACKUP
interface eth1
virtual_router_id 105
priority 50
advert_int 1
authentication {
auth_type PASS
auth_pass secret
}
virtual_ipaddress {
192.168.10.100 dev eth1
}
notify_master “/bin/sh /etc/keepalived/lvs_master.sh”
notify_backup “/bin/sh /etc/keepalived/lvs_backup.sh”
}
————————————-
mysqlが落ちて、かつマシン(vrrp)が動いている場合、フェイルオーバが効かないので、mysqlが落ちた時に自身のkeepalivedを落とすスクリプト(PHP)を作成。
こちらからのまるパクリです。
# touch /etc/keeplalive/mysql_alivecheck.php
————————————-
hostname‘;
// 成功したときに実行したいコマンド
$SUCCESS_BIN = ”;
$result = db_connect_check($HOST, $USER, $PASS, $DB_NAME);
if (!$result) {
// 失敗
print “error\n”;
if ($FAIL_BIN) {
system($FAIL_BIN);
}
} else {
// OK
if ($SUCCESS_BIN) {
system($SUCCESS_BIN);
}
}
exit;
function db_connect_check($host, $user, $pass, $db_name) {
$con = mysql_connect($host, $user, $pass, true);
if (!$con) {
// エラー表示
print mysql_error();
return false;
}
if ($db_name) {
if (!mysql_select_db($db_name, $con)) {
// エラー表示
print mysql_error();
return false;
}
}
return true;
}
?>
————————————-
※これはPHPの例だが、”mysqladmin -ping”でチェックするshellスクリプトなどでもOK。
CRONに登録
# vi /etc/crontab
————————————-
*/1 * * * * root php /etc/keeplalive/mysql_alivecheck.php;
————————————-
CRONじゃなくループでまわしちゃいたいときなどは下記参照。
http://d.hatena.ne.jp/bose999/20100926/1285440284
ていうか、こういうスクリプト走らせなくても、keepalivedのvirtual_serverディレクティブで自分のリアルIPの3306ポート監視して、notify_downでkeepalived落とせばいいんじゃないの?って思った。
↓こんな風に。
http://d.hatena.ne.jp/interdb/20131219/1387380530
試してませんが。
最後にkeepalivedの自動起動設定
# chkconfig keepalived on
あとは必要に応じてiptablesで規制をするなどしてください。
今回許可が必要なのはtcp、以下MySQL、vrrp、icmpくらい。
必要に応じてHTTP,DNSなど。
# 参考サイト
http://sonarsrv.com/blog/server/server_debian/344.html
http://d.hatena.ne.jp/bose999/20100925/1285408588
http://d.hatena.ne.jp/bose999/20100926/1285440284
http://qiita.com/nagais/items/b9b1940cdaf9a17b4088
http://infra.makeall.net/archives/1475
http://infra.makeall.net/archives/1607
http://infra.makeall.net/archives/1665
http://knowledge.sakura.ad.jp/tech/274/3/
http://knowledge.sakura.ad.jp/tech/274/4/
http://tanyaolinux.blogspot.jp/2014/04/vip-permanent.html
http://k-1-ne-jp.blogspot.jp/2013/02/lvsipvsadm.html
http://q.hatena.ne.jp/1199870913
http://d.hatena.ne.jp/interdb/20131219/1387380530
http://rksz.hateblo.jp/entry/2013/03/19_keepalived_lvs_load_balancer_2013
http://oxynotes.com/?p=6361#2
http://techblog.raccoon.ne.jp/archives/47152095.html