随時更新中。
- HTMLタグをエスケープ無しで出力(デフォルトではエスケープされる)
|
1 |
{{ html | raw }} |
※管理上の都合により2015年11月以前の記事は削除いたしました
文字列省略(Twig1.6以降)
|
1 2 |
{{# 32文字目まで表示して残りは...にする #}} {{ name | length > 32 ? name | slice(0, 32) ~ '…' : name }} |
HTML参照文字エスケープ
|
1 2 3 |
{{ html | e }} {{# または、#}} {{ html | e("html") }} |
リプレース
|
1 2 3 |
{{ "I like %this% and %that%." | replace({'%this%': foo, '%that%': "bar"}) }} {{ "I like this and --that--." | replace({'this': foo, '--that--': "bar"}) }} |
改行文字をbrに
|
1 |
{{ text | nl2br }} |
ループ
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
{## 基本形 ##} {% for Product in Products %} ID: {{ Product.id }} Name: {{ Product.name }} {% endfor %} {## キーだけ表示 ##} {% for Product in Products | keys %} key: {{ Product }} {% endfor %} {## キー,値をそれぞれ取得 ##} {% for ProductKey, ProductValue in Products %} key: {{ ProductKey }} value: {{ ProductValue }} {% endfor %} {## sliceと組み合わせたり ##} {% for key, value in ['太郎', '次郎', '三郎', '四郎', '五郎']|slice(2, 4) %} {{ key }}:{{ value }} {% endfor %} {# 0:三郎 1:四郎 2:五郎 #} |
ループの中で使える便利なやつ
|
1 2 3 4 5 6 7 |
{## loop.lastは、最後の要素の時true ##} {% for Product in Products %} ID: {{ Product.id }} Name: {{ Product.name }} {## 最後の要素じゃなかったらコンマ出力 ##} {{ loop.last ? '' : ',' }} {% endfor %} |
正規表現マッチング
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{# 基本形 #} {% if Product matches '{^abc$}' %} match! {% else %} not match! {% endif %} {# メタ文字(.や?など)エスケープ時はバックスラッシュ3つ #} {% if Product matches '{\\\?id=1234}' %} match! {% else %} not match! {% endif %} |
その他は随時更新。
参考URL)
あるメール配信で配信エラーになった場合に、相手先からどのようなエラーコードとバナーが返却されているかを調べるときに便利。
ちなみに、postfixのログは、一行ごとに、
|
1 |
日付 時刻 ホスト名 postfix/プロセス名[プロセスID]: キューID: 処理・・・ |
といった構造で書かれる。同じキューIDのログを調べれば、一通のメールの一連の動きを追うことが出来る。
直近の”to@hoge.com”宛てのメールのキューIDを取得するシェルスクリプト
|
1 2 3 4 5 6 7 8 9 10 |
#!/bin/bash # メールログの場所 MAILLOG_PATH='/var/log/maillog' # 宛て先でgrepして、sedでキューIDを抽出 qid=`cat "$MAILLOG_PATH" | grep -Eo "\[[0-9]+\]\: [A-Z0-9]+\:.*?to=<to\@hoge\.com>" | tail -1 | sed -r "s/^\[[0-9]+\]\: ([A-Z0-9]+)\:.*?$/\1/"` # 抽出したキューIDで再検索 logs=`cat "$MAILLOG_PATH" | grep $qid` echo $logs |
結果
|
1 2 3 4 5 6 |
May 8 19:**:** *** postfix/pickup[32062]: D361640567: uid=48 from=<from@fuga.com> May 8 19:**:** *** postfix/cleanup[32321]: D361640567: message-id=<20180508******.D361640567@fuga.com> May 8 19:**:** *** postfix/qmgr[1849]: D361640567: from=<from@fuga.com>, size=1098, nrcpt=1 (queue active) May 8 19:**:** *** postfix/smtp[32324]: D361640567: to=<to@hoge.com>, relay=***.***.com[***.**.**.**]:25, delay=0.2, delays=0.06/0/0.03/0.12, dsn=5.0.0, status=bounced (host ***.***.com[***.**.**.**] said: 550 Invalid recipient: <to@hoge.com> (in reply to RCPT TO command)) May 8 19:**:** *** postfix/bounce[32332]: D361640567: sender non-delivery notification: 1145640568 May 8 19:**:** *** postfix/qmgr[1849]: D361640567: removed |
ちなみに上記は「said: 550 Invalid recipient: <to@hoge.com>」と返ってきているので、メールを送ったこのユーザ(to@hoge.com>)は存在しなかったということになる。
ちなみに理想としては、エンベロープFROMに、宛て先と送信するたびの履歴番号など、特定の情報を仕込んでおくと、時系列で探しやすい。
sendmail使うなら、
|
1 |
echo -e "To: to@hoge.com\nFrom: from@fuga.com\nSubject: Hello world.\n\nHello world." | /usr/sbin/sendmail -t -f to=hoge.com-001@fuga.com |
とかしておくとよい。(この場合「to=hoge.com-001@fuga.com」がエンベロープFROM)
そうしておけば、何回も同じ宛先に送っている場合でも、下記のように目的のキューIDを探しやすくなる。
|
1 2 3 4 |
: # 宛て先でgrepして、sedでキューIDを抽出 qid=`cat "$MAILLOG_PATH" | grep -Eo "\[[0-9]+\]\: [A-Z0-9]+\:.*?from=<to=hoge\.com\-001\@" | head -1 | sed -r "s/^\[[0-9]+\]\: ([A-Z0-9]+)\:.*?$/\1/"` : |
なおヘッダーFROMをいくらいじっても、基本的にはメールログには記録されない。(ログレベルを上げればできるかも。この辺は調べてない。)
参考サイト)
このような目的場合、無償サイトだとこちらの「文字番号を入力して調べる」のツールが便利。1つ2つの変換であればこのサイトを利用したほうが早いです。
変換するコードが大量にある場合は、いろいろ方法はあるかと思いますが、あくまでユーティリティなので、エクセルでちゃちゃっと変換する方法を紹介します。
まず、変換したいUnicode(Unicode Code Point)を確認します。ここでは例として「(U+)3042」を変換します。これは、ひらがなの「あ」に相当します。
まず、このUnicodeは16進数ですので、2進数に変換します。この16進数は「30」と「42」に分けられますので、エクセルの関数ですと、
=HEX2BIN(LEFT(セル番号,2),8)&HEX2BIN(RIGHT(セル番号,2),8) ①
と書くことが出来ます。
2進数への変換後は、「0011000001000010」となります。
次にこの「(U+)3042」が、こちらのサイトの「表3-9 UnicodeとUTF-8の関係」のどの範囲に該当するか調べます。
今回の場合ですと、3042なので、表の3行目(00000800~0000ffff)の範囲に該当します。(16進数の大小関係が分からない方は、他サイトでお調べください)
 (出典: Hitachi, Ltd. 文字コード変換後の値の求め方)
(出典: Hitachi, Ltd. 文字コード変換後の値の求め方)
そして、1バイト目から3バイト目を、表に倣って変換します。表の「v」の数だけ、2進数をわけて考えるとわかりやすいです。
今回の場合だと、1バイト目がv4つ、2バイト目がv6つ、3バイト目がv6つですので、0011000001000010は、「0011」と「000001」と「000010」に分けられます。
これらの先頭に、表のように2進数を付け加えます。
1バイト目:「0011」の先頭に「1110」を加えて、「11100011」
2バイト目:「000001」の先頭に「10」を付け加えて「10000001」
3バイト目:「000010」の先頭に「10」を付け加えて「10000010」
これを全部繋げると、「111000111000000110000010」になります。(8bit×3=3byte文字)
ここで行った作業をエクセルの関数で書くと、
=”1110″&LEFT(セル番号,4)&”10″&MID(セル番号,5,6)&”10″&RIGHT(セル番号,6) ②
となります。
最後に、この2進数を、再度16進数に戻します。エクセルの関数で書くと、
=BIN2HEX(LEFT(セル番号,8))&BIN2HEX(MID(セル番号,9,8))&BIN2HEX(RIGHT(セル番号,8)) ③
となります。
最後に導き出された16進数文字「E38182」が、UTF-8変換後の文字コードとなります。
イメージとしては下記のような感じです。上記の①~③の関数が、以下の図の①~③に対応しています。
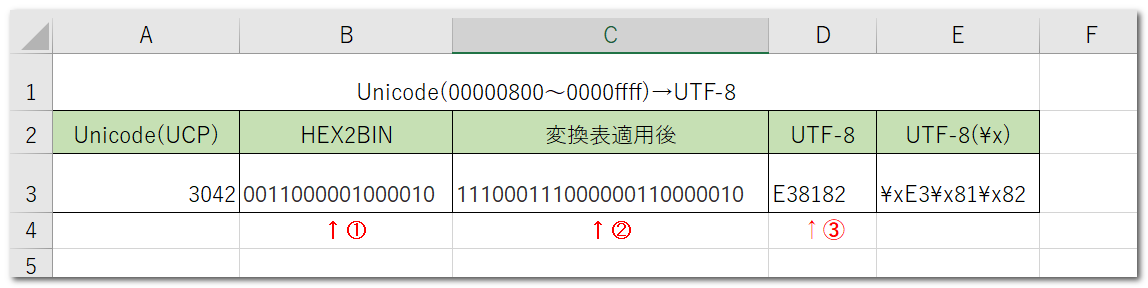
あとはオートフィルを使うなり、いろいろと出力を加工して大量の変換ができると思います。
Googleが推奨するhreflangタグ。SEO効果はほとんどないみたいだが、サーチコンソールに出るのが嫌な場合は対策が必要。
タグを設置するのは簡単だが、このタグはサイトごとではなくページ単位で有効なタグなので、ページ毎に設置する必要がある。その為、下層のページにはその下層のページのURLで設置する必要がある。
EC-CUBEの場合は、site_frame.tplに下記のように書くことで、下層を含む全ページに対応可能。(例では言語は’ja’のみ)
/data/Smarty/templates/default(またはsphoneなど)/site_frame.tpl
|
1 2 3 4 5 6 |
<head> : <!-- hreflangタグ (user_dataとindex.phpは省略) --> <link rel="alternate" hreflang="ja" href="http://www.hogehoge.com<!--{$smarty.server.PHP_SELF|replace:'user_data/':''|replace:'/index.php':'/'}-->" /> : </head> |
参考URL)
SELECTするとき、WHERE句で特定の日付の値を条件として使いたいが、その値が存在しなかったり期待するものと違ったりした時、別の日付をキーにする。
例えば以下は、base_dateカラムの日付をキーにしたいが、base_dateの値がNULLだったりMySQLのデフォルト値(0000-00-00)だったりすると、結果がおかしくなってしまう。
|
1 2 3 4 5 6 7 |
/* base_dateから数えて3日後の会員を取得 */ SELECT * FROM `tbl_user` WHERE DATEDIFF( CURRENT_DATE(), base_date ) = 3 |
なので、このbase_dateの値が期待するものと違えば、代替として、entryの値を使用したい。
CASEを使って対応。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/* base_dateから数えて3日後の会員を取得 */ /* base_dateがNULLまたは0000-00-00ならentryの値を使用 */ SELECT * FROM `tbl_user` WHERE DATEDIFF( CURRENT_DATE(), ( CASE WHEN base_date IS NULL THEN entry WHEN base_date = '0000-00-00' THEN entry ELSE base_date END ) ) = 3 |
NULLだけを回避するのであれば、COALESCEを使えばいいっぽい。試してないが書くならこんな感じかしら。
|
1 2 3 4 5 6 7 8 |
/* base_dateから数えて3日後の会員を取得 */ /* base_dateがNULLならentryの値を使用 */ SELECT * FROM `tbl_user` WHERE DATEDIFF( CURRENT_DATE(), COALESCE(base_date, entry) ) = 3 |
参考サイト)
Smartyのループの中で、現在何番目の処理かを知りたいときなどは、「index」プロパティを使用します。
|
1 |
$smarty.foreach.ループ名.index |
例)リスト10件おきに広告を表示したいとき
|
1 2 3 4 5 6 7 |
<!-- {foreach from=$personaldata item=var name=loopname} --> : <!-- { if($smarty.foreach.loopname.index + 1) % 10 == 0 } --> <!-- ここに広告 --> <!-- {/if} --> : <!-- {/foreach} --> |
参考URL)
GROUP BY で指定したカラムの値が、同じ値の行はグループ化されるが、GROUP BY で指定していないカラムの値は、どの行の値を優先させるか、通常は決めることができない。
例えば、下記のようなSQLだと、得られるidの優先順位は指定できない。(実際、昇順で最初のものがくる場合が多いが、保証はされない)
|
1 2 3 4 |
SELECT id, name, birthday FROM `tbl` GROUP BY birthday WHERE birthday > '1999/12/31' |
この場合は、副問い合わせで対応するのが一般的なやり方らしい。
|
1 2 3 4 5 6 7 8 |
SELECT id, name, birthday FROM `tbl` WHERE id IN( SELECT MAX(id) -- idで最大の値を取得 FROM `tbl` GROUP BY birthday WHERE birthday > '1999/12/31' ) |
ちなみにWHERE句で絞る場合も、副問い合わせの中で絞らないとダメ。なので、下記の場合は失敗する。
|
1 2 3 4 5 6 7 8 |
SELECT id, name, birthday FROM `tbl` WHERE id IN( SELECT MAX(id) -- idで最大の値を取得 FROM `tbl` GROUP BY birthday ) AND birthday > '1999/12/31' |
参考サイト)
比較的横幅の広い、中央寄せしている画像をサイトに掲載している場合、ホイールスクロールなどでサイトを拡大していくと、画像の幅が画面からはみだしたところで、画像が左端が画面の左端に合った状態で拡大されてしまう。
したがって、PCモニタの解像度によっては、デフォルト縮尺の状態でも、画像が中央から右にずれたような表示となってしまう。
この場合は、leftプロパティとネガティブマージンで対応する。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
div.box { overflow:hidden; width:1370px; height:300px; /* ↓ここ */ left: 50%; margin-left: -685px; /* ↑ここ */ } div.box img { width:1370px; height:300px; } |
(imgがブロック要素であればimgの方に指定してもよろしいかと思う。)
動作確認ブラウザ
参考サイト)
ファイル検索でよく使われるfindと併用するといいらしい。
|
1 |
$ find path -name filename -exec rm -fr {} \; |
WindowsのローカルからLinuxのリモートにSCPしたときに、余計な「desktop.ini」が一緒にアップされちゃったときとか。
|
1 |
$ find /home/user -name desktop.ini -exec rm -fr {} \; |